Flow-based generation in high-dimensional pixel spaces is difficult because velocity prediction requires modeling high-dimensional noise, even when data has strong low-rank structure. We present Asymmetric Flow Modeling (AsymFlow), a rank-asymmetric velocity parameterization that restricts noise prediction to a low-rank subspace while keeping data prediction full-dimensional. From this asymmetric prediction, AsymFlow analytically recovers the full-dimensional velocity without changing the network architecture or training and sampling procedures. On ImageNet 256×256, AsymFlow achieves a leading 1.57 FID, outperforming prior DiT/JiT-like pixel diffusion models by a large margin. AsymFlow also provides the first route for finetuning pretrained latent flow models into pixel-space models: aligning the low-rank pixel subspace to the latent space gives a seamless initialization that preserves the latent model's high-level semantics and structure, so finetuning mainly improves low-level mismatches rather than relearning pixel generation. Finetuned from FLUX.2 klein, AsymFLUX.2 klein establishes a new state of the art for pixel-space text-to-image generation, beating its latent base on HPSv3, DPG-Bench, and GenEval while qualitatively showing substantially improved visual realism.
AsymFlow achieves 1.76 FID with JiT-H/16 network and 1.57 FID with an additional REPA loss, outperforming prior DiT/JiT-like pixel diffusion models by a large margin.
Finetuned pixel AsymFLUX.2 klein shows improved visual styles and realism, beating the latent FLUX.2 klein base model on HPSv3, DPG-Bench, and GenEval.
Standard velocity prediction asks the network to predict \(u = \epsilon - x_0\), so both the data term and the noise term are full-dimensional. In uncompressed pixel space, this forces a transformer to represent high-dimensional noise that wastes model capacity.
AsymFlow changes the target to asymmetric velocity \(u_\mathrm{A} = P\epsilon - x_0\), where \(P\) is a patch-wise low-rank projector. The model predicts noise in a low-rank subspace and data in the full-dimensional space, then recovers the full velocity analytically. This reduces the burden of noise prediction.
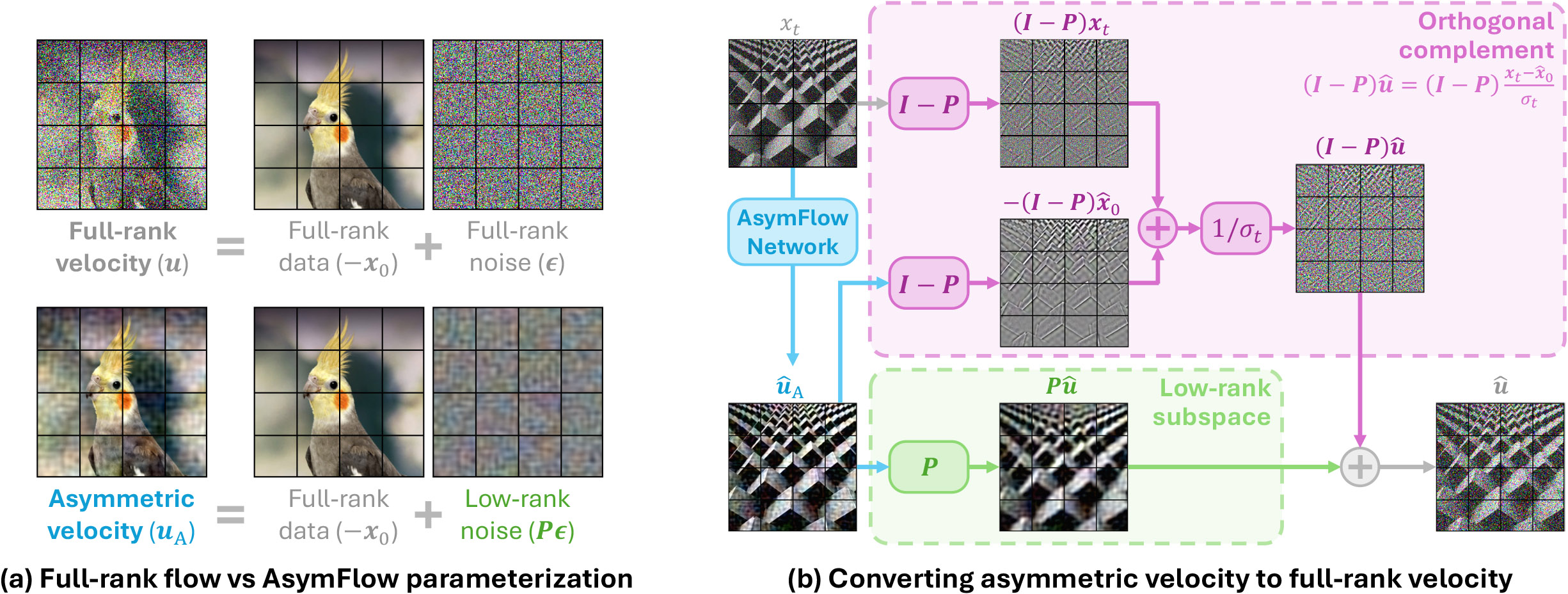
AsymFlow keeps the data term full-dimensional while restricting noise to a low-rank subspace.
\(u_\mathrm{A}\) can be decomposed into the low-rank subspace \(\mathrm{Im}(P)\) and its orthogonal complement \(\mathrm{Im}(I-P)\). The model effectively predicts \(u\) in the low-rank subspace and \(x_0\) in the orthogonal complement.
Thus, \(x_0\)-prediction is the zero-rank special case, and \(u\)-prediction is the full-rank special case. A small but non-zero rank is optimal as it retains the numerical stability and controllability of \(u\)-prediction in a meaningful subspace while reducing noise prediction difficulty.
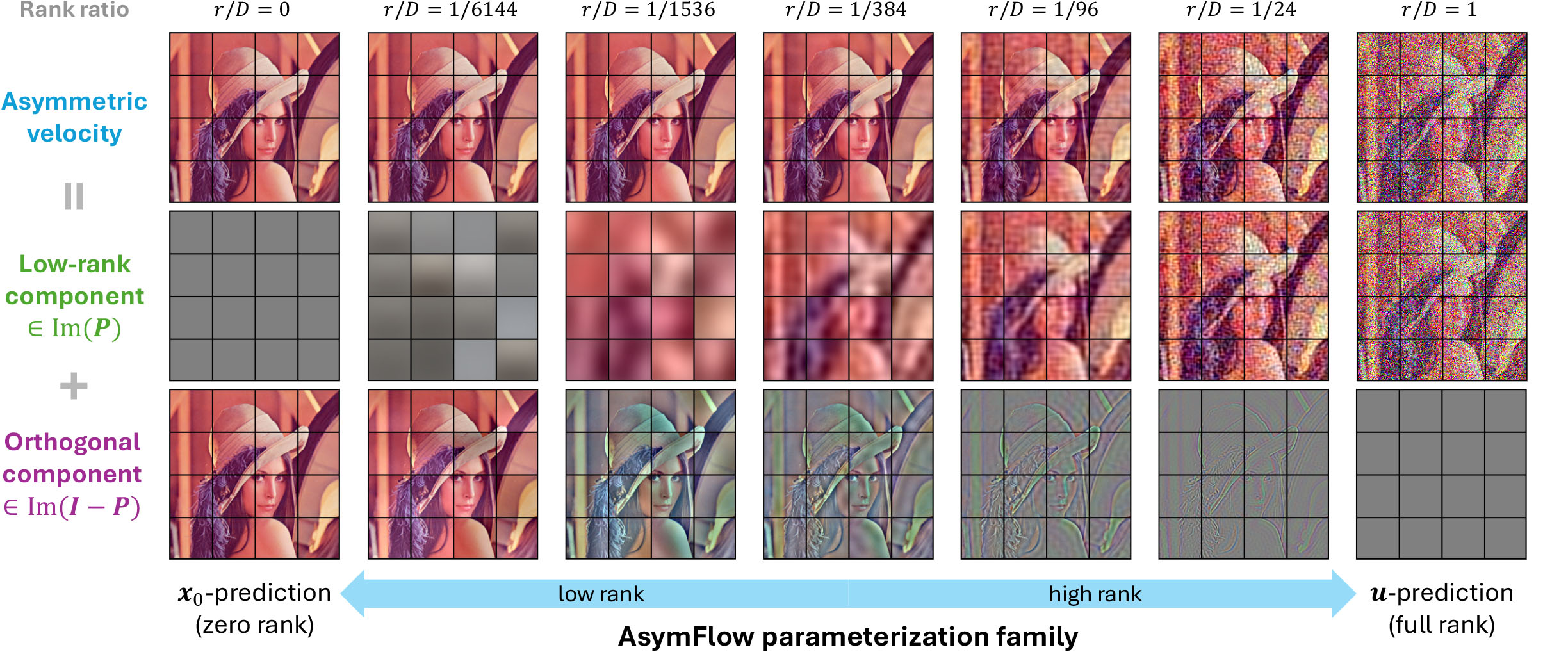
Varying the rank yields a parameterization family whose endpoints recover full \(x_0\)-prediction and full \(u\)-prediction.
By aligning the patch-wise low-rank pixel subspace with the latent space, AsymFlow can initialize a pixel model directly from a pretrained latent model. The initialized pixel denoising trajectory is coupled to the latent trajectory, so it already preserves high-level semantics and structure. Finetuning therefore mainly corrects low-level details and texture, rather than relearning text-to-image generation.
Using this initialization, we finetune FLUX.2 klein 9B into AsymFLUX.2 klein for pixel-space text-to-image generation. A variance-reduced flow matching objective with perceptual correction is adopted to improve fine detail and texture.

The lifted low-rank pixel initialization preserves the semantics and structure of the latent model.
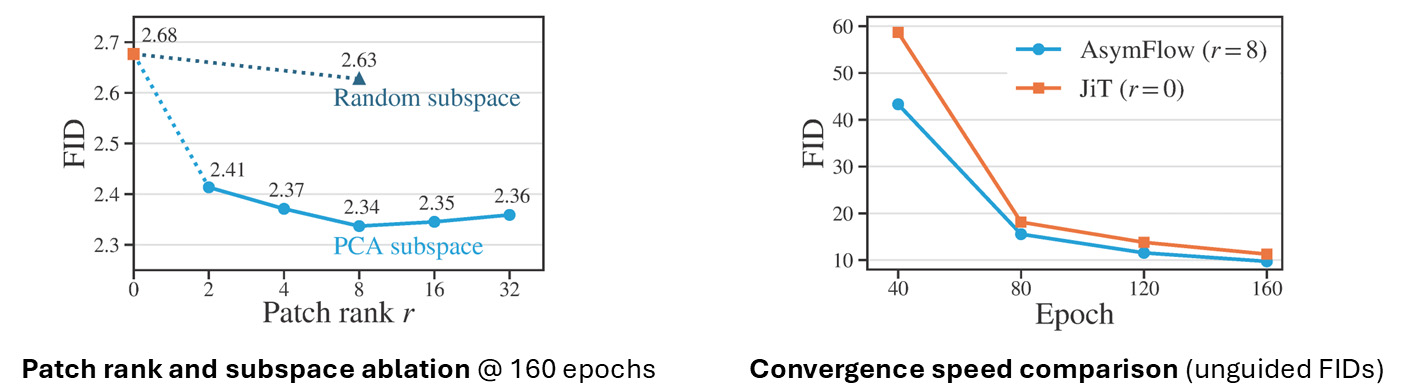
One ImageNet, AsymFlow improves over the \(x_0\)-prediction JiT baseline by a clear margin, reaching the best FID with patch rank 8.
| Method | Pred. (±) | Params | GFLOPs | FID↓ |
|---|---|---|---|---|
| Hierarchical CNNs (skip connections / U-Net-like) | ||||
| ADM-G | \(\epsilon\) | 554M | 2240 | 4.59 |
| Hierarchical transformers (skip connections / U-ViT-like) | ||||
| RIN | \(\epsilon\) | 320M | 668 | 3.42 |
| SiD, UViT/2 | \(\epsilon\) | 2B | 1110 | 2.44 |
| VDM++, UViT/2 | \(\epsilon\) | 2B | 1110 | 2.12 |
| SiD2, UViT/2 | \(\epsilon\) | - | 274 | 1.73 |
| EPG-G/16 | \(x_0\) | 1.4B | 642 | 1.58 |
| SiD2, UViT/1 | \(\epsilon\) | - | 1306 | 1.38 |
| Hierarchical transformers (decoder head / DDT-like) | ||||
| PixNerd-XL/16 | \(\epsilon - x_0\) | 700M | 268 | 2.15 |
| DiP-XL/16 | \(\epsilon - x_0\) | 631M | - | 1.79 |
| DeCo-XL/16 | \(\epsilon - x_0\) | 682M | 245 | 1.62 |
| PixelDiT-XL/16 | \(\epsilon - x_0\) | 797M | 311 | 1.61 |
| Plain transformers (DiT-like) | ||||
| PixelFlow-XL/4 | \(\epsilon - x_0\) | 677M | 5818 | 1.98 |
| JiT-H/16 | \(x_0\) | 953M | 363 | 1.86* |
| PixelGen-XL/16 | \(x_0\) | 676M | 260 | 1.83 |
| JiT-G/16 | \(x_0\) | 2B | 766 | 1.82* |
| PixelREPA-H/16 | \(x_0\) | 953M | 363 | 1.81* |
| AsymFlow-H/16 | \(P\epsilon - x_0\) | 953M | 363 | 1.57 |
FLOP estimation follows the convention in PixelDiT. * denotes JiT evaluation protocol, which may have slightly better FID than ADM.
| Method | HPSv3↑ | DPG↑ | GenEval↑ |
|---|---|---|---|
| Latent diffusion models | |||
| SDXL | 8.20 | 74.7 | 0.55 |
| PixArt-\(\Sigma\) | 9.37 | 80.5 | 0.54 |
| Hunyuan-DiT | 8.19 | 78.9 | 0.63 |
| FLUX.1 dev | 10.43 | 84.0 | 0.67 |
| Qwen-Image | 9.52 | 87.8 | 0.86 |
| FLUX.2 klein Base | 9.50 | 85.2 | 0.80 |
| Pixel diffusion models | |||
| PixelDiT-T2I | 8.95 | 83.5 | 0.74 |
| AsymFLUX.2 klein | 10.66 | 86.8 | 0.82 |
All text-to-image evaluations generate 1024×1024 images.

Pixel AsymFLUX.2 klein produces more realistic styles and textures that distinguish it from latent diffusion models.
@article{chen2026asymmetric,
title={Asymmetric Flow Models},
author={Hansheng Chen and Jan Ackermann and Minseo Kim and Gordon Wetzstein and Leonidas Guibas},
journal={arXiv preprint arXiv:2605.12964},
url={https://arxiv.org/abs/2605.12964},
year={2026},
}